



Data Observability
Monitor data at rest for ensure data is complete and fresh. Pre-configured monitors and machine learning frameworks are available out of the box providing immediate value to customers.

Data Volume
Machine learning based anomaly detection monitoring for missing data with automated root-cause analysis

Data Freshness
Machine learning based anomaly detection monitoring for stale data with automated root-cause analysis
Operational Observability
Monitor data in motion for broken pipelines including job failures, data latency, and not started jobs. Pre-configured monitors and machine learning frameworks are available out of the box providing immediate value to customers.

Data Latency
Automated real-time monitoring on how on-time or
delayed data is while moving across the pipeline
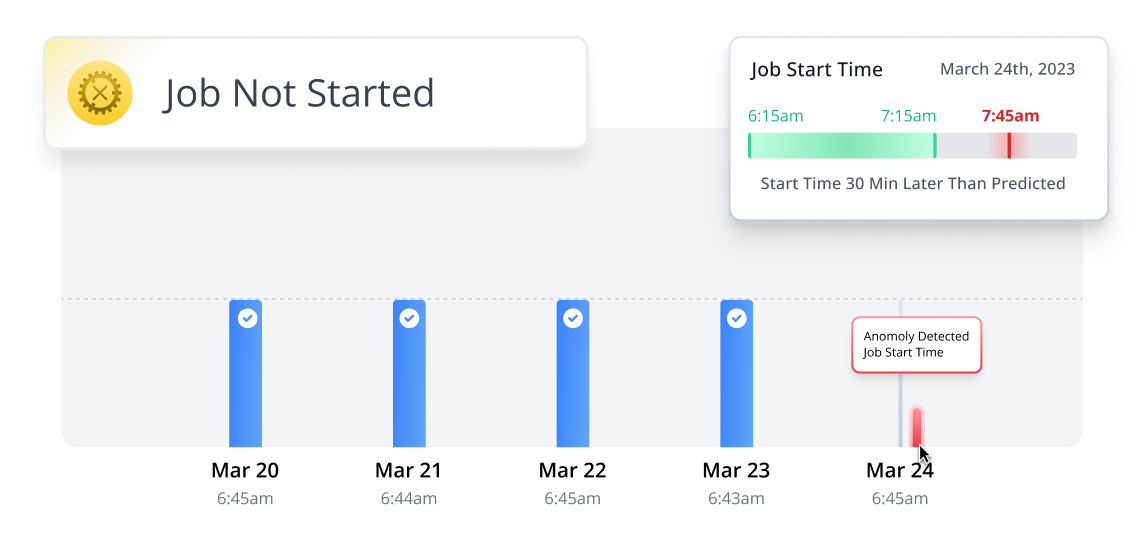
Not Started Jobs
Monitor jobs in real-time to make sure they start on schedule
within auto-configured thresholds

Failures
Monitor job failures in real-time with automated impact
analysis and root-cause analysis
Data Profiling & Quality
Receive automated insights into key dataset characteristics like column counts and variable types. Leverage platform specific data profiling and data quality procedure generation for in line checks within a customizable framework.
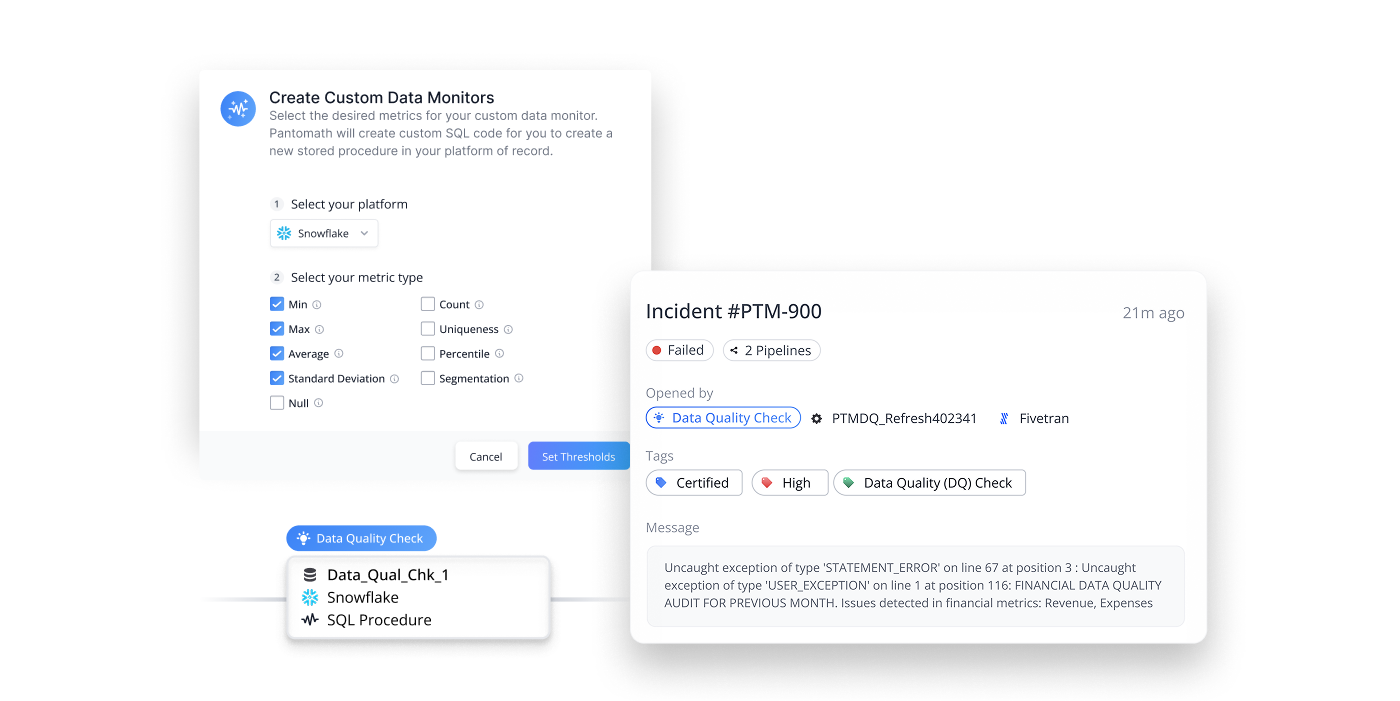
Custom In-Line Quality & Profiling Rules
Integrate custom data quality and profiling checks
seamlessly within your data pipelines with a user
friendly drag-and-drop experience for creating checks for both data engineers and business users alike without sacrificing control.
Intelligent Anomaly Detection
Directly integrate procedure outputs into Pantomath’s automated ML-based monitoring capabilities to detect anomalies within datasets, alerting you to changes and ensuring ongoing data integrity.
Automated Profiling
Out of the box data profiling checks, including the column counts, column variable types, total records, etc. for immediate insights into data structure.
Traceability Across The Data Pipeline
Automated cross-platform pipeline lineage from data producers to data consumers with every interdependency and relationship mapping across the data stack.
Application-level technical job lineage and data lineage together make up cross-platform pipeline lineage.

Job Catalog
Designed to centralize and organize your entire data ecosystem. From jobs and tables to pipelines and tags (alongside operational and business documentation) our catalog offers a unified view of all your data assets.
Simplify data discovery with powerful search capabilities, ensuring stakeholders across your organization can find and understand the data they need, when they need it.
.png)
Unified Data View
Access a centralized overview of your data
landscape across platforms, including jobs, tables, pipelines, and documentation.
Intelligent Anomaly Detection
Directly integrate procedure outputs into Pantomath’s automated ML-based monitoring capabilities to detect anomalies within datasets, alerting you to changes and ensuring ongoing data integrity.
Automated Profiling
Out of the box data profiling checks, including the column counts, column variable types, total records, etc. for immediate insights into data structure.


