

What is a data operations center?
Learn MoreWhat is a data operations center?
Learn More

Data Observability: Key Concepts
Data Observability is the ability to monitor and understand the health of an organization’s data, data pipelines,and overall data landscape, to reduce downtime and promote data reliability.
Traditional tools focus on static data stored in databases or warehouses, but modern approaches prioritize data in motion—monitoring data as it flows through pipelines and across platforms. This involves identifying anomalies, resolving issues in real-time, and ensuring smooth data operations in complex systems. To achieve true end-to-end effectiveness, data observability is enriched by two key components:
- Operational observability monitors pipeline issues such as latency, job failures, stale or missing data.
- Pipeline traceability captures cross-platform data lineage, connecting datasets, jobs, and their dependencies.
For example, imagine a sales dashboard showing outdated revenue metrics. Data observability might flag this as a data freshness issue, while operational observability pinpoints the root cause—a delayed ETL job. Pipeline traceability then reveals the upstream jobs or datasets affected, enabling teams to resolve the problem and mitigate its impact.
A modern data observability solution should be able to detect a data quality issue, pinpoint the operational root cause, provide insights into other potential impacts, and make remediation recommendations.
This article explores the core components of data observability, including key observations, critical metrics, and advanced capabilities like operational observability and pipeline traceability. It concludes with best practice recommendations for implementing data observability.
Summary of key data observability concepts
#1 Key pillars of data observability
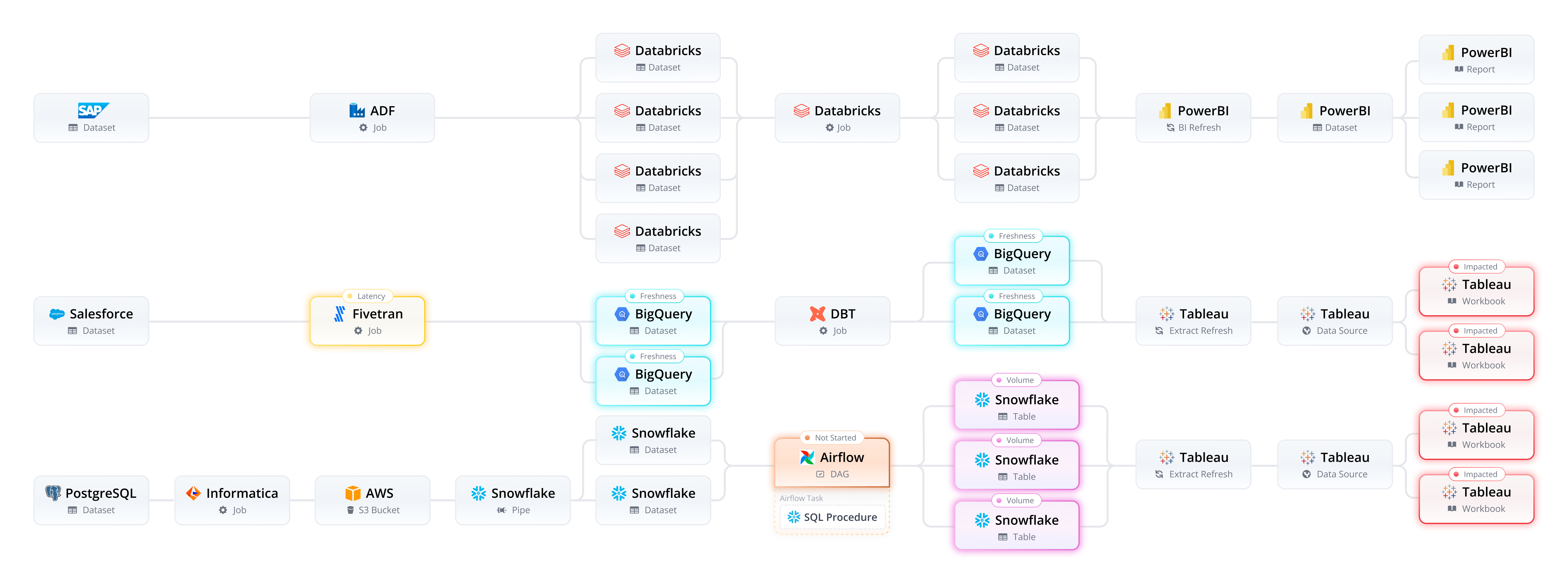
Modern data pipelines have become more complex because they comprise multiple tools, such as Snowflake, Apache Spark, Airflow, Microsoft PowerBI, and AWS Glue. Integrating various tools across multiple teams makes pinpointing and resolving issues difficult.
Modern data observability addresses this challenge by monitoring the entire data pipeline, from source to consumer, including data in motion and the operational aspects of the pipeline.
As such, the pillars of modern data observability include:
- Data Quality: Monitors data values and accuracy, which is the overarching goal.
- Data Profiling: Analyzes data distribution and characteristics.
- Data Observability: Data is monitored at rest for completeness and freshness in traditional data pipelines, though this term is also used broadly in the industry, as we will explain later in this article.
- Operational Observability: Monitors data in motion, job executions, and latency.
- Pipeline Traceability: Pinpoints the operational root cause of data quality issues.
# 2 Key dimensions of data observability
Data observability spans several dimensions critical to ensuring the health and reliability of modern data systems. Here we discuss key observations a comprehensive data observability solution should enable:

Data content
Monitoring data content involves ensuring the accuracy, timeliness, relevance, and accessibility of datasets across the data pipeline. For instance, a dataset with missing values or delayed updates can cause dashboards to display outdated or incorrect metrics, potentially leading to poor decision-making. This can be addressed through automated checks such as null value analysis, timestamp validations, and schema validation to ensure the completeness and correctness of data as it lands in the system.
Data flow and pipeline
Observing data flow and pipeline performance includes tracking throughput rates, pipeline error rates, execution times, and data drift. These observations help identify bottlenecks and anomalies in data movement. For example, a sudden drop in throughput may indicate a bottleneck in a specific pipeline transformation step. At the same time, data drift (unexpected changes in data distributions) can disrupt downstream processes. Such issues can be detected by profiling pipeline outputs, setting up latency thresholds, and employing real-time monitoring tools to flag disruptions promptly.
Below, we share an example of how Pantomath can log pipeline metrics using its pre-built integrations with popular data management tools.
Infrastructure and compute
Ensuring the optimal performance of infrastructure and compute resources requires monitoring latency, traffic, and system saturation. Delays in data processing or job failures often trace back to overloaded compute resources or network bottlenecks. For example, investigating compute saturation metrics can reveal resource limitations when pipelines run slower than expected. This can be managed by leveraging workload-aware scheduling systems and implementing resource utilization dashboards to monitor and adjust infrastructure capacity proactively.
User, usage, and utilization
Understanding how data is consumed requires tracking usage patterns, lineage, permissions, and metadata (tags). These insights help organizations evaluate data utilization and align it with business objectives. For instance, a sudden increase in data queries from a specific team might indicate a shift in operational priorities or the presence of inefficient queries. This can be managed by auditing user access and query patterns, refining permissions, and using lineage tracking tools to map dataset dependencies and access frequency.
Financial allocation (FinOps and cost observability)
Cost observability involves monitoring resource consumption, cost-per-query, and capacity planning to ensure efficient spending. For example, a pipeline with an unusually high cost-per-query might indicate suboptimal resource usage or inefficient transformations. Real-time cost monitoring dashboards can help identify and resolve these issues, while predictive models using historical trends enable better capacity planning and prevent unexpected budget overruns.
#3 Metrics for effective data observability
The next step is to tie the observations described in the previous section to tangible metrics. The figure below illustrates how these observations can be aligned to the metrics.
Let’s discuss the key metrics that should be captured to ensure comprehensive observability coverage of your data estate. This has also been discussed in detail here.
Data volume
Data volume measures the total amount of data processed, stored, or transmitted, along with its rate of change. This metric helps predict storage and processing needs, enabling infrastructure scaling and capacity management.
Example: An e-commerce platform processes an average of 1 million transactions daily. A sudden spike to 1.5 million may indicate a marketing campaign's success, while a drop to 500,000 could flag a service outage.
How to Achieve: Implement row count checks and rate-of-change monitoring. Automated models are used to establish baseline metrics and configure alert thresholds.
Data freshness
Data freshness ensures datasets are up-to-date, preventing the use of stale information in decision-making. Metrics such as timestamp analysis, recency, and expiry are often monitored.
Example: A bank updates account balances every minute to ensure real-time fraud detection. Any delay beyond the SLA triggers a freshness alert.
How to Achieve: Use timestamp validation and data age checks. Set SLAs for freshness based on business needs and industry benchmarks.
Data completeness
Completeness verifies that datasets include all required fields and records, ensuring accurate and reliable analyses.
Example: A sales dataset missing product IDs renders revenue analyses incomplete. Schema validation can detect these anomalies.
How to achieve: Use null value analysis, required field checks, and schema validation tools to ensure data integrity.
{{banner-large-2="/banners"}}
Data latency
Latency tracks the delay between data creation and availability. This metric is critical for real-time decision-making, particularly in time-sensitive industries like finance and e-commerce.
Example: An analytics dashboard shows delayed updates because of high pipeline processing times. Monitoring end-to-end processing latency helps detect and resolve these issues.
How to achieve: Monitor query response times and real-time data delivery rates. Implement alerting systems for latency thresholds.
Data movement
Data movement measures data transfer across systems, including speed, frequency, and success rate. This ensures smooth and reliable pipeline operations.
Example: Data transfer between on-premise and cloud environments slows due to network congestion. Monitoring transfer speeds can pinpoint the bottleneck.
How to achieve: Track data transfer volume, frequency, and success rates. Use dashboards to visualize movement trends and detect anomalies.
Data accuracy
Accuracy ensures that datasets correctly reflect real-world values. Inaccurate data undermines business decisions and impacts critical functions like reporting and compliance.
Example: A financial reporting error occurs when transactional data and aggregated totals differ. Cross-referencing datasets can catch such issues.
How to achieve: Implement validation rules, statistical checks, and historical comparisons to ensure data accuracy.
Job operations
Job operations monitor the health of data processing workflows, including job failures, latency, and scheduling. Healthy job operations are key indicators of pipeline reliability.
Example: A delayed ETL job prevents downstream data updates, leading to dashboard inaccuracies. Monitoring job latency and success rates helps identify root causes.
How to achieve: Use workflow orchestration tools to monitor job performance and set alerts for failures or delays.
Cross-platform data pipeline lineage
Lineage tracks the flow of data and its transformations across systems, providing visibility into dependencies and enabling root-cause analysis.
Example: A report error is traced back to a misconfigured upstream transformation. Lineage tracking helps visualize the impact across the pipeline.
How to achieve: Leverage lineage tools that map data and job dependencies across platforms, capturing metadata and transformation details.
Mean time to detection (MTTD)
MTTD measures how quickly issues are identified after they occur. Faster detection minimizes downstream impacts.
Example: A sudden drop in data volume is flagged within minutes, preventing prolonged service disruptions.
How to achieve: Automate anomaly detection and alerting to reduce detection times. Use historical trends to fine-tune thresholds.
Mean time to resolution (MTTR)
MTTR tracks the time taken to resolve issues, from detection to resolution verification. Faster resolution improves system reliability.
Example: A pipeline failure caused by compute saturation is resolved in 30 minutes after alerts are triggered. Reduced MTTR minimizes operational disruptions.
How to achieve: Implement real-time monitoring solutions and maintain thorough documentation for faster troubleshooting. Supplement with user training.
#4 Modern end-to-end data observability
Modern data observability must go beyond static monitoring to include real-time insights and dynamic capabilities. At its core, it integrates advanced functionalities like Operational Observability and Pipeline Traceability, enabling data teams to achieve a truly comprehensive view of data systems and pipelines. These capabilities form the backbone of modern end-to-end data observability, empowering organizations to ensure data quality, reliability, and timely issue resolution.

Operational observability
Operational observability monitors pipelines in motion, providing real-time insights into critical metrics like data latency, job performance, and resource utilization. It allows data teams to proactively detect, analyze, and resolve pipeline issues. Key aspects of operational observability include:
- Data latency: Automated real-time monitoring ensures data moves through the pipeline on time. Delays or bottlenecks can be flagged immediately, minimizing disruptions to downstream systems.
Example: An alert is triggered when a data processing stage exceeds its latency threshold, indicating potential resource saturation.
- Data movement: Real-time monitoring verifies the completeness and accuracy of data in motion. Ingested records are automatically validated, reducing the risk of missing or incomplete datasets propagating through the pipeline.
Example: A notification highlights discrepancies in the number of records ingested during a scheduled data load.
- Not started jobs: Jobs that fail to start on schedule can disrupt the entire pipeline. Operational observability includes automated checks to ensure that jobs initiate within predefined thresholds. This could also initiate retries.
Example: An automated alert detects a job that hasn’t started, preventing downstream tasks from running on incomplete data.
- Failures: Real-time monitoring of job failures enables automated impact and root-cause analysis, reducing the time required to address pipeline issues.
Example: A job failure is flagged with detailed logs identifying insufficient compute resources as the root cause.
Pantomath is purpose-built for operational observability. It offers automated real-time monitoring, latency tracking, and impact analysis to help data teams address pipeline challenges efficiently.
Pipeline traceability
Pipeline Traceability provides cross-platform lineage by connecting datasets and jobs, offering a detailed view of dependencies and transformations. It is the only way to understand the journey of data across a pipeline fully, enabling data teams to manage complexity and resolve issues quickly. Pipeline Traceability enables:
- Root cause analysis: By mapping data lineage and job dependencies, pipeline traceability pinpoints where and why a problem occurred. Whether it’s a failed job or a schema change at the consumer layer, data teams can quickly isolate the issue.
Example: Tracing a failed query to an upstream data source reveals that a schema change disrupted compatibility, allowing the team to resolve it efficiently.
- Impact analysis and resolution: Pipeline traceability maps every interdependency within the pipeline, helping data teams understand the full impact of an issue. This insight allows them to identify which jobs to re-run, which dashboards are affected, and how to return the pipeline online.
Example: A failed ETL job’s downstream impact is visualized, showing which datasets and dashboards were affected and enabling rapid resolution.
Pantomath offers pipeline traceability, combining data lineage with application-level job lineage to give data teams a complete view of dependencies, impacts, and required fixes. Learn more about the distinctions between data and pipeline traceability here.

Combining operational observability and pipeline traceability ensures both the health of data in motion and a comprehensive understanding of its journey across systems. Together, they elevate traditional static data observability by enabling real-time issue detection, actionable root cause analysis, and impact resolution. In today’s complex data environments, these capabilities are essential for maintaining reliability and trust in data pipelines.
{{banner-small-3="/banners"}}
#5 Challenges in achieving end-to-end data observability
Integrating diverse systems (silos)
Modern data ecosystems span multiple platforms, such as Snowflake, Databricks, and legacy on-premise systems. These silos hinder the ability to derive a unified view of data health and pipeline performance. For example, a downstream dashboard issue might require correlating metrics from Databricks transformations with Snowflake ingestion logs, which can be challenging without unified APIs or cross-platform observability tools.
Scaling for large datasets and complex pipelines
As data pipelines scale in size and complexity, the overhead for capturing, processing, and analyzing observability logs increases. Monitoring a highly distributed ETL pipeline processing terabytes of data daily can lead to compute overhead that slows pipeline execution. To address this, efficient log sampling and scalable storage solutions must be employed, ensuring observability systems don’t become bottlenecks themselves.
Parsing complex logs and aligning to metrics
Logs from distributed systems are often unstructured, making it difficult to derive actionable insights. For instance, identifying the root cause of a delayed query may require correlating fragmented logs from storage, compute, and orchestration layers. Centralized log aggregation and automated parsing tools, such as those leveraging natural language processing (NLP), can simplify this process and align logs with meaningful metrics.
Maintaining alert relevance
Excessive alerts from observability systems lead to alert fatigue, where teams ignore notifications, risking missed critical issues. For example, a pipeline generating alerts for every minor data drift might overwhelm engineers. To maintain relevance, observability systems must prioritize critical alerts by leveraging anomaly detection models and configurable thresholds, reducing noise while surfacing actionable incidents.
Handling multiple levels of drift
Drift across different layers—such as code, data, schema, and infrastructure—can disrupt pipelines and introduce errors. For instance, a schema change in the data source layer might propagate downstream, breaking ETL jobs or dashboards. The accompanying figure highlights these potential breakpoints across application, data, control, and infrastructure planes. Addressing drift requires real-time monitoring for changes and automated impact analysis to identify affected dependencies promptly.
Data governance challenges
Observability systems must comply with privacy and access regulations. For example, a data engineer troubleshooting a pipeline should only have visibility into metadata or data subsets permitted by their IAM role or RBAC policies. This ensures sensitive information is protected while enabling effective debugging. Observability tools need to integrate seamlessly with governance frameworks to enforce these constraints.
Scope for improving the interpretation of observability metrics
Observability systems provide data but do not inherently solve issues, making metrics challenging to interpret. For example, a latency metric flagged as “high” might not specify whether the cause is a compute resource bottleneck or an upstream data delay. Automated insights, such as root cause identification and actionable recommendations, can bridge this gap, making metrics more meaningful for teams.
#6 Best practices for end-to-end data observability
Making alerting intuitive and actionable
Alerts should provide value by being precise and offering actionable insights. For instance, systems should specify the impacted pipeline stage rather than generate generic latency alerts and suggest remediation steps. By setting thresholds and prioritizing critical alerts, observability can serve data engineers and support teams and business users who depend on actionable information.
Leveraging existing tools and SDKs
Building observability pipelines incrementally using platform-specific SDKs allows teams to avoid reinventing the wheel. For example, tools like Pantomath’s SDK or suite of connectors can integrate seamlessly with existing workflows, databases, storage locations, or BI tools, enabling faster deployment of observability features and reducing development overhead.
AI/ML-based acceleration
Incorporating AI/ML models enhances observability by enabling predictive monitoring and anomaly detection. For instance, a model that predicts potential data drift based on historical trends can allow teams to act preemptively, minimizing disruptions. Similarly, ML-powered automated log analytics can identify root causes more efficiently.
Start small and scale incrementally
Achieving comprehensive observability can be overwhelming, so starting with high-impact use cases is critical. For example, focusing on monitoring key revenue-generating pipelines first ensures immediate value. Gradually expanding observability coverage as the system scales allows for better resource utilization and reduced complexity.
Automate routine tasks
Manual tasks such as monitoring job schedules or validating data completeness can consume significant engineering bandwidth. Automating these processes ensures consistency and frees up teams for higher-value tasks. For instance, automated anomaly detection can flag missing records without requiring engineers to inspect logs manually.
Ensure team training and collaboration
Observability insights are only effective if teams can interpret and act on them. Equipping data engineers and business users with the necessary training ensures smooth collaboration and effective resolution of issues. Regular workshops and shared dashboards can foster cross-functional understanding, enabling faster and more efficient troubleshooting.
{{banner-small-4="/banners"}}
Last thoughts
Achieving effective data observability requires monitoring not just the data but also the pipelines, compute infrastructure, and costs. Enabling data observability with operational observability and pipeline traceability can ensure root cause analysis. This article outlined the observations, metrics, challenges, and best practices to build proactive observability systems, enabling engineers to detect, trace, and resolve issues more efficiently.



{kind=link}
{kind=link}
{kind=link}