


Data Pipeline Design Best Practices
Data pipeline design has dramatically evolved over the past decade. Traditionally, data pipelines moved data from online transaction processing (OLTP) databases to online analytical processing (OLAP) databases for further analysis. These jobs were usually monolithic modules running on some self-managed computing environment and confined to technologies provided by one or two vendors such as Oracle.
In comparison, today’s data pipelines comprise components provided by multiple commercial vendors and open-source technologies, such as Apache Airflow, Apache Spark, AWS Glue, Snowflake, and Microsoft PowerBI, to name a few, hosted across public and private clouds. The data pipelines are also more diverse, spanning batch, micro-batch, poll-based, and streaming types. Depending on business needs, each type comes with unique requirements, operational challenges, and design considerations.
The increased complexity brings difficulties in observation and troubleshooting. When a pipeline fails unexpectedly, data engineers must manually collect and analyze logs from multiple jobs. Sometimes, all jobs are completed successfully, but the outcome is intermittently wrong. The cause can be harder to diagnose, and data engineers must sift through execution logs to identify the root cause.
This article introduces the best practices for designing data pipelines based on modern observability and traceability best practices. If you want to learn about pipeline automation concepts before reading this article, you can start with the first chapter of this guide, which introduces a framework with an overview of automation concepts.
Summary of key data pipeline design concepts
Beginning data pipeline design
Any pipeline design starts by identifying the pipeline type you’re working with—batch, poll-based, or streaming. Each type requires a distinct approach to design, scalability, error handling, and optimization. For instance:
- Batch pipelines are designed for large, periodic data processing jobs focusing on throughput and volume.
- Streaming pipelines handle real-time data and focus on latency and immediacy.
- Poll-based pipelines work at intervals, frequently querying data sources, and need specific optimization for resource usage.
These distinctions also affect the infrastructure requirements and how jobs are scheduled.
For example, in Apache Airflow (an open-source platform released in 2015 for developing and scheduling data pipeline jobs at scale), you typically schedule batch pipelines using cron jobs or time-based triggers, while streaming pipelines may require custom sensors or event-based triggers.
The code below demonstrates a simple batch pipeline in Airflow that runs once a day, scheduled using a cron-like @daily interval, which ensures the pipeline starts at midnight UTC every day. The DAG (Directed Acyclic Graph, explained here) structure consists of a starting dummy task (start) and an ending dummy task (end), connected in a linear sequence. The catchup=False parameter ensures that Airflow will not backfill any missed pipeline runs.
from airflow import DAG
from airflow.operators.dummy_operator import DummyOperator
from airflow.utils.dates import days_ago
default_args = {
'owner': 'airflow',
'start_date': days_ago(1),
'retries': 1
}
with DAG(
dag_id='batch_pipeline_example',
default_args=default_args,
schedule_interval='@daily', #see this interval which makes this pipeline run on cron once a day
catchup=False,
) as dag:
start = DummyOperator(task_id='start')
end = DummyOperator(task_id='end')
start >> endOur second code example implements a similar job scheduling functionality but does it in the popular Snowflake platform. This example showcases Snowflake’s features such as JavaScript support in stored procedures, task scheduling, and resource management used for building automated ETL pipelines.
This code automates a basic ETL (Extract and Load) process, where data is extracted from a source table and inserted into a target table daily at midnight. The stored procedure handles errors and provides feedback on whether the ETL process was successful or if it encountered issues.
-- Create a stored procedure for the ETL process
CREATE OR REPLACE PROCEDURE batch_etl_procedure()
RETURNS STRING
LANGUAGE JAVASCRIPT
AS
$$
try {
// Extract data
var extract_query = `INSERT INTO target_table (id, name, created_at)
SELECT id, name, created_at FROM source_table;`;
snowflake.execute({sqlText: extract_query});
return 'ETL process completed successfully.';
} catch (err) {
return 'ETL process failed: ' + err;
}
$$;
-- Create a task to run the stored procedure daily at midnight UTC
CREATE OR REPLACE TASK batch_pipeline_example
WAREHOUSE = 'COMPUTE_WH'
SCHEDULE = 'USING CRON 0 0 * * * UTC'
AS
CALL batch_etl_procedure();{{banner-large="/banners"}}
Precedence dependencies and their impact on pipeline design
When you design a complex data pipeline, the first thing to do is identify the precedence dependencies between various jobs in the pipeline. Each job has one or more data sources and data targets. The target for job A can be the source for job B. In this case, we say job B depends on job A. As such, job B shall not start execution until job A successfully finishes execution.
The precedence dependencies in a data pipeline can be formally represented by a directed acyclic graph (DAG). Each node in the DAG represents a job, while the edge connecting two nodes represents the precedence dependency between the two jobs. Note that a DAG has directions—the job on the END side of the DAG cannot start running until the job on the START side of the DAG.
Figure 1 shows a DAG for a simple data pipeline with three jobs. When the pipeline is started, Job 1 and Job 2 can run in parallel. Job 3 depends on both Job 1 and Job 2 - it can not start execution until both Job 1 and Job 2 successfully finish execution. Here, the START and END jobs are dummy jobs whose purpose is to illustrate the direction of the data pipeline.
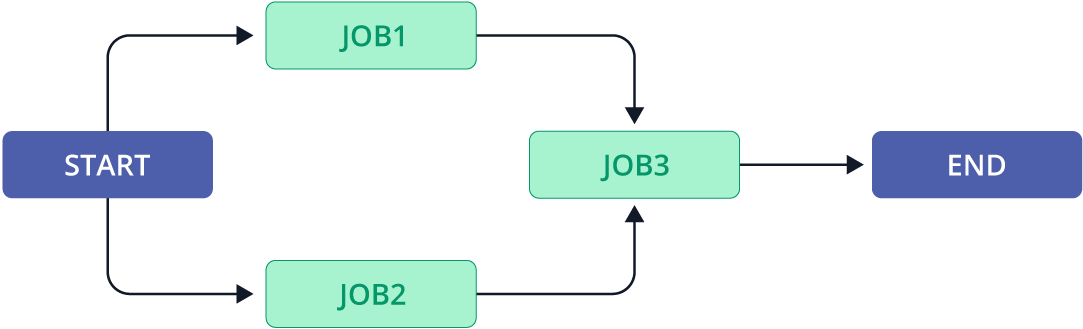
As shown in Figure 1, a DAG helps visualize the structure of the data pipeline. When we detect an error with a specific job, we can look at the DAG to shortlist upstream jobs that might be causing the problem and downstream jobs that the problem might impact. Having a DAG also paves the foundations for advanced discussions on data lineage, pipeline lineage, pipeline traceability, and pipeline observability.
Pre-validation checks
In addition to understanding the flow of tasks in a DAG, implementing pre-validation checks at key points in your pipeline design ensures the successful execution of those tasks. These checks validate critical components before tasks within the DAG are triggered, reducing the likelihood of failure due to missing or misconfigured resources. Pipelines often fail due to missing or misconfigured components, such as absent database tables, incorrect data types, or missing constraints. Implementing pre-validation checks avoids costly reprocessing and minimizes the need for job retriggers due to data inconsistencies.
For example, the code snippet demonstrates pre-validation checks at the beginning of an Airflow pipeline.
from airflow.operators.python_operator import PythonOperator
from sqlalchemy import create_engine, inspect
DB_URI = 'mysql://user:password@host:port/db'
def pre_validation():
engine = create_engine(DB_URI)
try:
# Check database connection
with engine.connect() as connection:
pass # Connection is successful if no exception is raised
inspector = inspect(engine)
required_table = 'target_table'
# Check if the required table exists
if required_table not in inspector.get_table_names():
raise Exception(f"Table '{required_table}' is missing.")
# Check columns and data types
expected_columns = {
'id': 'INTEGER',
'name': 'VARCHAR',
'created_at': 'DATETIME'
}
columns = {col['name']: col['type'].__class__.__name__.upper() for col in inspector.get_columns(required_table)}
if set(columns.keys()) != set(expected_columns.keys()):
raise Exception(f"Column mismatch in '{required_table}'")
for col_name, col_type in expected_columns.items():
if columns[col_name] != col_type:
raise Exception(f"Type mismatch for column '{col_name}'")
if not inspector.get_pk_constraint(required_table)['constrained_columns']:
raise Exception(f"Primary key constraint is missing in '{required_table}'")
expected_foreign_keys = ['customer_id'] # Example
foreign_keys = {fk['constrained_columns'][0] for fk in inspector.get_foreign_keys(required_table)}
if set(expected_foreign_keys) != foreign_keys:
raise Exception(f"Foreign key constraints mismatch in '{required_table}'")
expected_indexes = ['idx_name', 'idx_created_at']
index_names = {idx['name'] for idx in inspector.get_indexes(required_table)}
if not set(expected_indexes).issubset(index_names):
raise Exception(f"Missing required indexes in '{required_table}'")
except Exception as e:
raise Exception(f"Pre-validation failed: {e}")
pre_validation_check = PythonOperator(
task_id='pre_validation',
python_callable=pre_validation,
dag=dag
)The code defines a pre_validation() function that verifies database integrity and configuration before running the main pipeline. It checks for:
- Successful database connection
- Presence of a required table
- Valid column names and data types
- Primary key and foreign key constraints
- Necessary indexes.
A PythonOperator performs these checks before proceeding with the rest of the DAG.
For a second example of validation checks, we will use Python in an AWS Glue environment. This code sets up a data pipeline using AWS Glue and PySpark to validate and load data into a MySQL database. It validates the target database schema before performing an ETL load, ensuring data integrity and aligning with the expected structure before inserting new data. It checks for:
- Table existence: Ensures target_table exists in the database.
- Column structure: Verifies expected columns (id, name, created_at) and their data types.
- Primary key constraint: Confirms the table has a primary key.
- Foreign key constraints: Verifies specific foreign keys (e.g., customer_id).
- Indexes: Checks if required indexes (idx_name, idx_created_at) are present.
import sys
import boto3
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.utils import getResolvedOptions
from sqlalchemy import create_engine, inspect
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
DB_URI = 'mysql://user:password@host:port/db'
def pre_validation():
engine = create_engine(DB_URI)
try:
# Check database connection
with engine.connect() as connection:
pass # Connection is successful if no exception is raised
inspector = inspect(engine)
required_table = 'target_table'
# Check if the required table exists
if required_table not in inspector.get_table_names():
raise Exception(f"Table '{required_table}' is missing.")
# Check columns and data types
expected_columns = {
'id': 'INTEGER',
'name': 'VARCHAR',
'created_at': 'DATETIME'
}
columns = {col['name']: col['type'].__class__.__name__.upper() for col in inspector.get_columns(required_table)}
if set(columns.keys()) != set(expected_columns.keys()):
raise Exception(f"Column mismatch in '{required_table}'")
for col_name, col_type in expected_columns.items():
if columns[col_name] != col_type:
raise Exception(f"Type mismatch for column '{col_name}'")
if not inspector.get_pk_constraint(required_table)['constrained_columns']:
raise Exception(f"Primary key constraint is missing in '{required_table}'")
expected_foreign_keys = ['customer_id'] # Example
foreign_keys = {fk['constrained_columns'][0] for fk in inspector.get_foreign_keys(required_table)}
if set(expected_foreign_keys) != foreign_keys:
raise Exception(f"Foreign key constraints mismatch in '{required_table}'")
expected_indexes = ['idx_name', 'idx_created_at']
index_names = {idx['name'] for idx in inspector.get_indexes(required_table)}
if not set(expected_indexes).issubset(index_names):
raise Exception(f"Missing required indexes in '{required_table}'")
except Exception as e:
raise Exception(f"Pre-validation failed: {e}")
# Execute pre-validation
pre_validation()
# Continue with the main ETL process
transformed_df = source_df.filter("status = 'active'")
# Load data into target table
transformed_df.write.format("jdbc").options(
url=DB_URI,
dbtable="target_table",
user="user",
password="password"
).mode("append").save()Concurrent pipeline processing
Once the DAG is structured and validated, the next step is efficiently handling data volumes and processing loads. Depending on the size of the datasets, parallel task execution becomes key to meeting SLAs for timely execution and optimal resource utilization. Concurrency and parallelism allow different parts of the DAG to run simultaneously, particularly when tasks do not have interdependencies. These concepts ensure that pipelines process large datasets efficiently while also preventing resource overload or bottlenecks.
For large datasets, parallel processing and concurrency become key considerations. They ensure the pipeline meets the Service Level Agreements (SLAs) around execution time and resource usage.
For instance, you can manage pipeline parallelism in Airflow using parameters like max_active_runs and concurrency. These settings help ensure that multiple jobs can run simultaneously without overloading the system. Here’s an Airflow snippet that configures pipeline concurrency
dag = DAG(
'parallel_pipeline_example',
default_args=default_args,
schedule_interval='@daily',
catchup=False,
max_active_runs=3, # Ensures max of 3 active runs at the same time
concurrency=10 # Max 10 tasks will run concurrently
)Understanding data pipeline jobs
Once the precedence dependencies between various jobs are identified, we need to develop a thorough understanding of every pipeline job.
- A batch job processes data in relatively big chunks, and the data is relatively old when it arrives at the job.
- A streaming job processes data in relatively small pieces, and the data is relatively fresh when it arrives at the job.
The difference between batch and streaming can lead to different design considerations, including recovery time objectives (RTO) and recovery point objectives (RPO).
5W1H framework
Let’s consider the 5W1H problem-solving and information-gathering framework that prompts users to ask six key questions—who, what, where, when, why, and how—to understand a situation thoroughly. You can use it to understand pipeline jobs in detail.
Figure 2 demonstrates how we use the 5W1H framework to analyze a job with two data sources and one data target. For each data source, we ask questions such as:
- Who owns the dataset?
- What is in the dataset?
- Where is the dataset?
- When is the dataset changed?
- Why has the dataset changed?
- How has the dataset changed?
- How does the job connect to the dataset?
- How do you read from the dataset?
You can explore this concept more here.
For the ETL jobs, we ask questions such as who owns the application, what the application does, where the application is executed, when the application is executed, how is the application triggered, and why do we need this step in the pipeline, what is the expected size of the dataset, whether there is a service level agreement (SLA), etc. If you are processing a large amount of data with a tight SLA, you likely need to split the data into multiple partitions and adopt a parallel processing approach to meet the SLA. For the data target, we ask questions such as who owns the dataset, what is in the dataset, where the dataset is, how the job connects to the dataset, and how to write to the dataset.
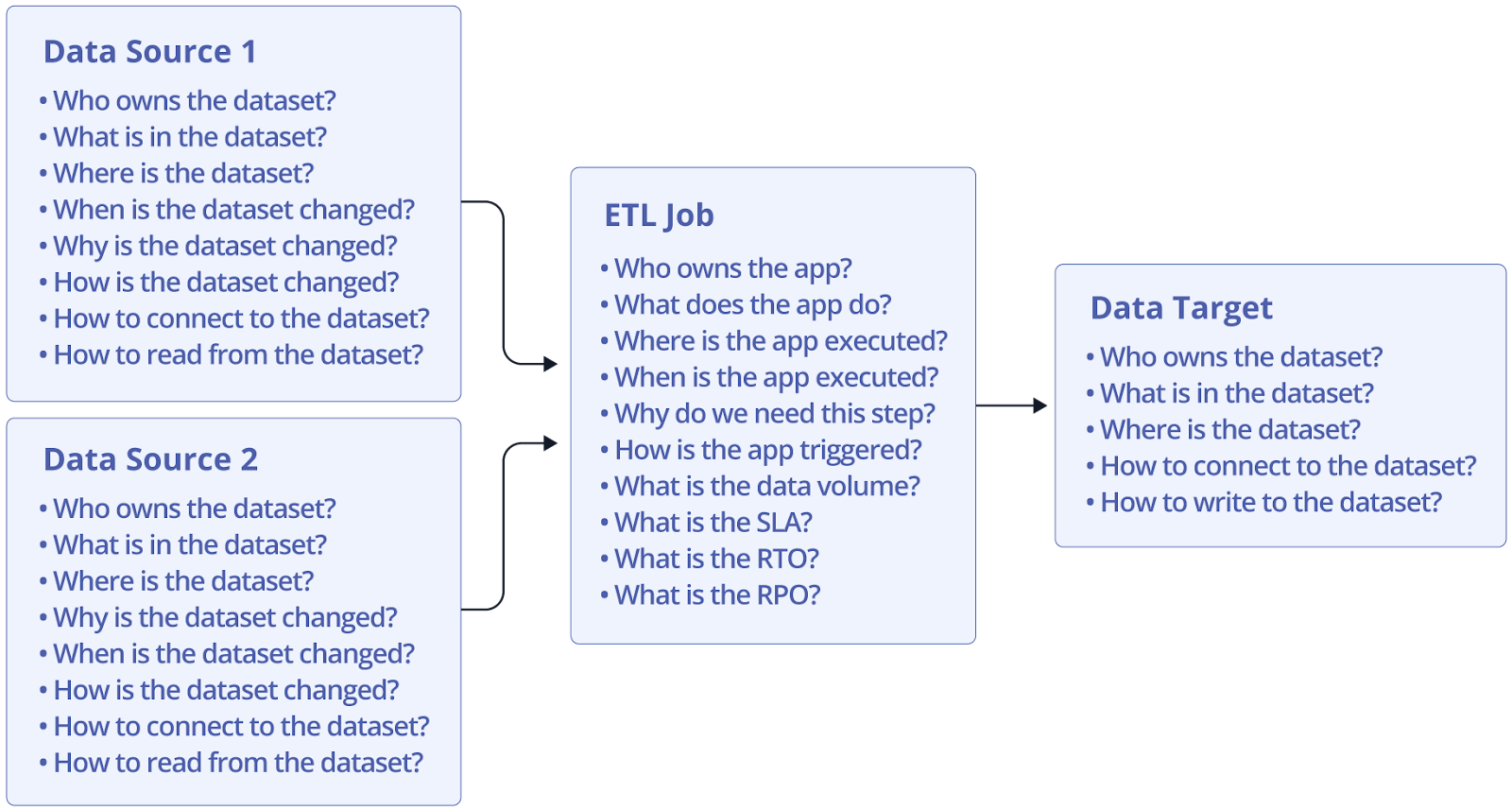
Apart from the questions listed above, more information can be obtained by asking additional questions. For example, you can dive deeper into the computing environment hosting the dataset by asking questions such as:
- What is the computing capacity of the computing environment
- What is the workload pattern in the computing environment
- Can the computing environment be scaled to meet the computing needs of various applications?
With regard to “how to read/write from/to the dataset,” you can also dive deeper into the SQL statements to understand the potential resource consumption on the data source/target. For example, you may wrongly presume that a job only reads from the data source. However, if the job performs JOIN, UNION, or ORDER BY at the data source, these queries likely generate disk writes on the computing environment hosting the data source.
Data pipeline design for failure recovery and contingency
Failure is a stochastic process that is neither avoidable nor predictable. In the words of Werner Vogels - Vice President and Chief Technology Officer of AWS—“Everything fails, all the time.” The question is how you can quickly identify and recover from the cause of failure without impacting end users.
The same applies to data pipeline design. In the context of an ETL job, failure can occur at the data source, the application, the data target, or in some component between the application and the data source/target. Planning for failure means (Contingency plan):
- Understanding the failure mode of different components
- Anticipating failures will occur
- Creating standard operating procedures (SOP) to troubleshoot and handle those failures when they do occur.

Identifying failure modes
Let’s assume we have a simple ETL job, as shown in Figure 3. The ETL application runs on an EC2 instance, with the data source being a MySQL database and the data target being Amazon S3. Below is a partial list of potential failure modes for the various components.
Your application code should catch all known exceptions and produce the necessary error message to assist in troubleshooting.
For example, if the job fails with out-of-memory errors, it is unlikely that a re-run will be successful on the same computing resource. Similarly, if the job fails due to insufficient disk space, it is unlikely that a re-run will be successful by upgrading to an EC2 instance type with more memory.
Thoroughly identifying failure modes in the design phase allows you to create standard operating procedures to deal with them. When failure occurs in a production environment, you can compare the error message with known signatures to identify the failure mode, then follow the standard operating procedure to mitigate the issue within the desired recovery time objective (RTO).
Automating error resolution
In modern enterprise pipelines, automating error resolution is key to minimizing downtime and manual intervention. Auto remediation refers to the pipeline's ability to detect and correct failures without human input.
For example, if a task fails due to a database connection issue, a self-healing pipeline can automatically retry the connection or switch to a backup resource. In data pipelines, jobs can occasionally fail in the middle of execution, requiring reprocessing of older or missing data. This process, known as backfilling, ensures that gaps in the data are filled while preventing duplication. Automated backfilling requires coordinating task dependencies to identify the proper data sources and distinguishing between already-processed and unprocessed data to avoid duplication.
In this example, Pantomath identifies the root cause of the problem by triangulating data lineage with operational monitoring. Pantomath’s pipeline traceability feature makes backfilling simpler as it visualizes failed or incomplete jobs to accelerate their recovery. It also helps ensure that all related downstream processes are included in the backfill. Learn more about how pipeline traceability can support this use case.
Data pipeline monitoring
The failure modes identified in the previous step form the foundation of our monitoring strategy. Below is a partial list of the situations you can monitor for the simple ETL job.
You can use the monitoring data to establish the baseline for the start time, execution time, and end time of the ETL job. The baseline then serves as the foundation for issue detection. For example, a contextual alert is generated to remind data engineers that something might be wrong if the job does not start or finish within the expected time frame. Such early warning identifies potential issues promptly, leading to a shorter time to resolution.
For a complex data pipeline with many jobs, it is likely that these jobs are owned by different teams, run on different platforms, and have different monitoring and alert mechanisms. The coordination challenge results in the lack of a systemic view of the end-to-end pipeline.
For example, many data engineers use cron jobs to trigger the execution of ETL jobs at specific times, with the implicit assumption that all upstream jobs are completed promptly. When an upstream job A fails or simply does not complete on time, the downstream job B is unaware of the situation. Job B assumes that the dataset at the data source is up-to-date, continues to execute based on stalled data, and produces the wrong output to the data target. Job C, further downstream, is completely unaware of the situation; it takes the output of job B and produces the wrong output for jobs further downstream or reporting.
This example describes a challenge commonly encountered by data engineering teams when dealing with complex data pipelines. For application owners, technical details about individual pipeline jobs are unimportant. Instead, they need a holistic view of:
- How the data evolves when it flows over the pipeline
- What is stopping the data from flowing?
- What is the impact when the data stops flowing?
In data pipeline terminologies, they care about pipeline lineage, which combines data lineage (the data provenance and journey) and pipeline operational observability (such as detecting failed or delayed jobs) to identify the root cause of data pipeline incidents.
Every pipeline run should include a post-validation task that generates a report for easy monitoring after it has been completed. This ensures that the data output meets both business and technical requirements. You can verify that the correct data amount has been processed and that key metrics align.
As introduced in the next section, Pantomath can automate the post-validation process by continuously monitoring data quality.
{{banner-large="/banners"}}
The 5 pillars of data observability in data pipeline design
Pantomath represents a new generation of pipeline automation. It automates the management of end-to-end pipeline lineage, which combines data lineage with data quality checks and operational pipeline observability to provide a unified view of the entire data ecosystem, including alerting and root cause analysis.
One of Pantomath’s key differentiators is its ability to augment data lineage with pipeline traceability, which helps identify the data journey through the pipeline and correlate operational failures (such as a failed job) with data quality problems (such as missing data) to identify the root cause and proactively notify data engineers.
Read Pantomath’s blog explaining the five pillars of data observability illustrated below to learn more about its approach to enforcing data quality in complex enterprise environments and read this article to explore the key data observability metrics.
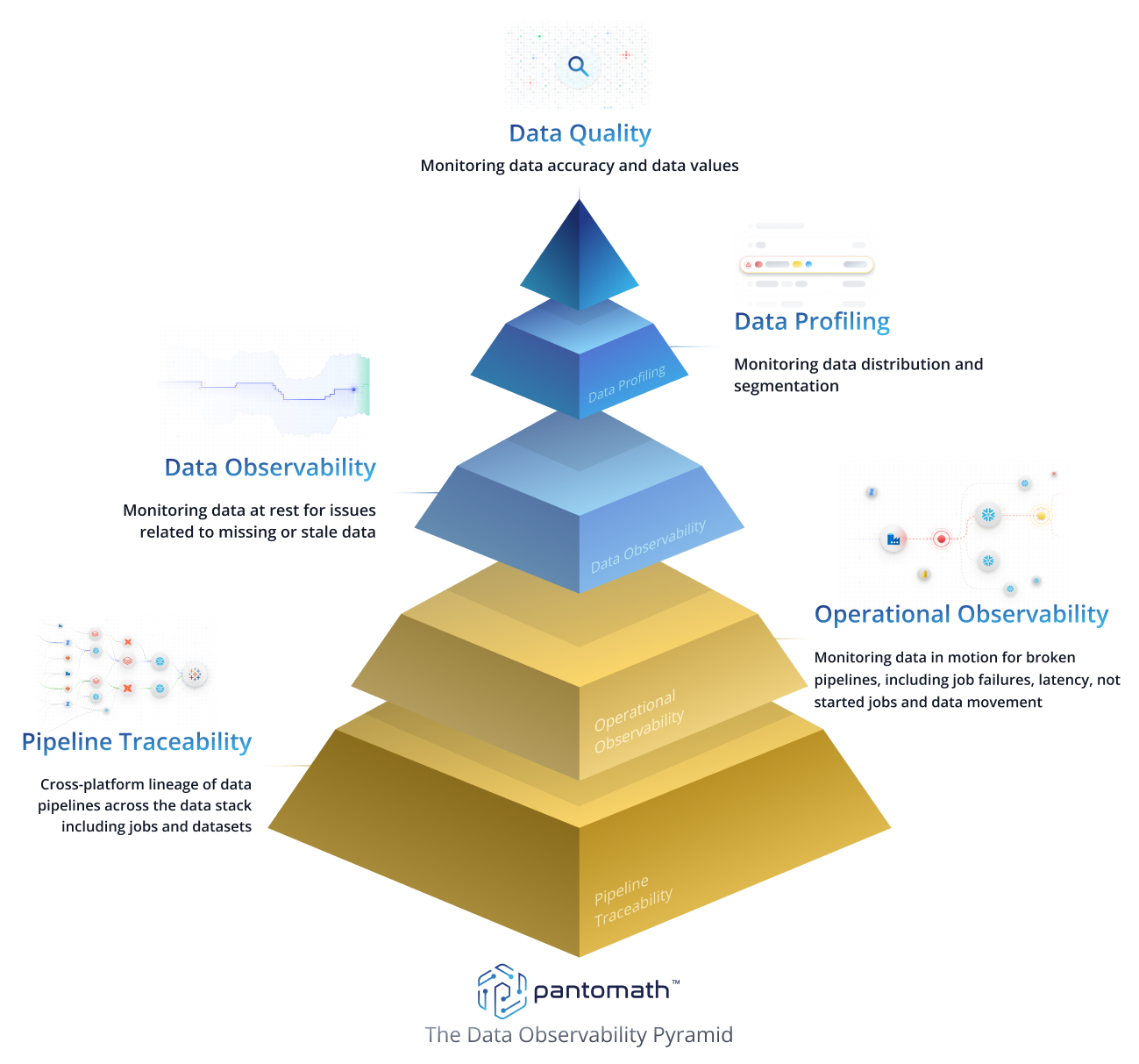
{{banner-small-1="/banners"}}
Last thoughts
This article offered guidance on designing data pipelines with observability and traceability in mind. Assuming that all jobs in the pipeline implement the same technical stack and run on the same platform, it is not too difficult to produce a unified view of the entire pipeline. Most traditional data pipeline automation frameworks adopt such an assumption, and they work well when the jobs in the pipeline are owned and managed by a dominating team.
However, different teams or organizations own different components in a complex pipeline. Every group has its own technical and organizational preferences. As a result, different jobs are implemented using different technical stacks and run on different platforms. This makes end-to-end observability and traceability difficult. This is where innovative data pipeline automation frameworks like Pantomath can help to ensure data operations are uninterrupted and data quality targets are met.
